|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
![]()
Authors: F. Cazals and R. Tetley
Structural motifs. Structural alignment methods for polypeptide chains aim at identifying conserved structural motifs between structures.
Global structural alignment methods often fail to exploit local properties, i.e. locally conserved distances. Phrased differently, for similarity measures such as 
This package provides a method identifying locally conserved hierarchical structural motifs shared by two polypeptide chains whose structure is known. In a nutshell:

Applications involving structural motifs. Motifs may be used to compute combined 
In the sequel, we recall the main concepts and the four steps used to identify motifs, referring the reader to [46] for the details.
For the sake of conciseness, we use structure and polypeptide chain interchangeably; likewise, structural motif and motif are used interchangeably.
Consider two polypeptide chains 




The alignment consists of pairs of a.a. mapped with one another, and can be computed using various methods. In this package, we use the following two aligners:


Denoting 



Note that these distances qualify the conservation of distances between
In mathematics, a filtration is a (finite) sequence of nested spaces [89] . Our method uses a filtration which may be the conserved distances (CD) filtration or the space filling diagram (SFD) filtration.
Conserved distances (CD) filtration. For each molecule, consider a graph whose vertices represent a.a., and edges are associated with all pairs of a.a (complete graph). Each edge is weighted by the score 
To each edge weight–say 

Space filling diagram (SFD) filtration. Molecular models defined by union of balls are called space filling diagrams (SFD). Geometric and topological properties of such diagrams are encoded in the so-called 
Upon sorting the scores
For each molecule, to each index–say 

Persistence diagram. For either filtration, let us focus on connected components, which appear and disappear when inserting edges (CD filtration) or a.a. (SFD filtration). A union-find data structure can be used to maintain these c.c. [66], and track in particular the birth date and the death date of each component.
The collection of all these points 

To compute persistence diagrams, we use the Morse_theory_based_analyzer package.
As previously stated, for each structure we compute a persistence diagram, respectively denoted 

Two points located in the same region of their respective PD have comparable birth and death dates. We identify such pairs of points. Denote 




When two points are comparable, we identify motifs as follows:
First, we compute the connected components associated to the sublevel set of the graph (CD filtration), or SFD (SFD filtration).
Second, we perform a structural alignment between all pairs of connected components. We distinguish the cases of homologous proteins and that of conformations:




As detailed in [46] , motifs are filtered in two ways:
As detailed in [46], motifs can be used to compute the edge-weighted 
As explained above, the detection of motifs hinges on two ingredients:
Combining these yields four methods:






These four methods are implemented within the following executables: each giving access to the CD and SFD filtrations:



We illustrate how to run the program on one executable since all behave in the same manner.
Input. In a nutshell:
Main options. The main options are:


Main output. As stated in Introduction, we report motifs for each structure. Each motif is identified by a unique motif id .
The main files output are as follows:
Motifs file, xml file, suffix __persistent_motifs.xml : XML Archive of all the found structural motifs. The archive provides two pieces of information. First, one finds statistics on the global alignment between the two chains. Second next, one finds the following pieces of information for every structural motif:
Nb: the python module Structural_motifs defines classes to parse this file and retrive the information on motifs. See also the script sbl-structural-motifs-analyzer.py, described below.
serialization seen in the file *persistent_motifs.xml done by class SBL::Modules::T_Pairwise_structural_alignment_module from file Pairwise_structural_alignment_module.hpp
Motifs diagram, GraphViz file, suffix hasse_diagram_one.dot: Hasse diagram of motifs. Each motif is identified with a unique index.
(todo) Motifs graph, xml file, suffix motif_graph.xml: XML Archive of the so-called motif graph (see Molecular_distances_flexible)
Additional files of interest are:
As a first example, we illustrate the conformational change undergone a prototypical class II fusion protein, from the tick-borne encephalitis virus. The ectodomain of this protein was crystallized both in soluble form (PDB: 1SVB, 395 residues) and in postfusion conformation (PDB: 1URZ, 401 residues).
For these structures, the identity alignment identifies 376 a.a., with a reference lRMSD of 1.13 – see yellow lines on Fig. fig-rigid-blocks-confs .
We run the executable as follows:
./sbl-structural-motifs-conformations.exe --motif-size 30 --lrmsd-threshold 0.8 --allow-incomplete-chains -p 4 --pdb-file pdb/1svb.pdb --chains A --pdb-file pdb/1urz.pdb --chains A --log -d 1svb-1urz
and generate the plots with
sbl-structural-motifs-analyzer.py -d 1svb-1urz
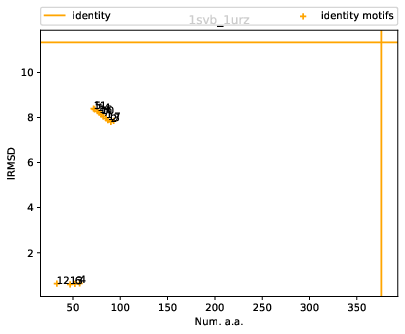 |
| Rigid blocks for 1n75/chain A vs 3afh/chain A: size (number of a.a.) versus lRMSD |
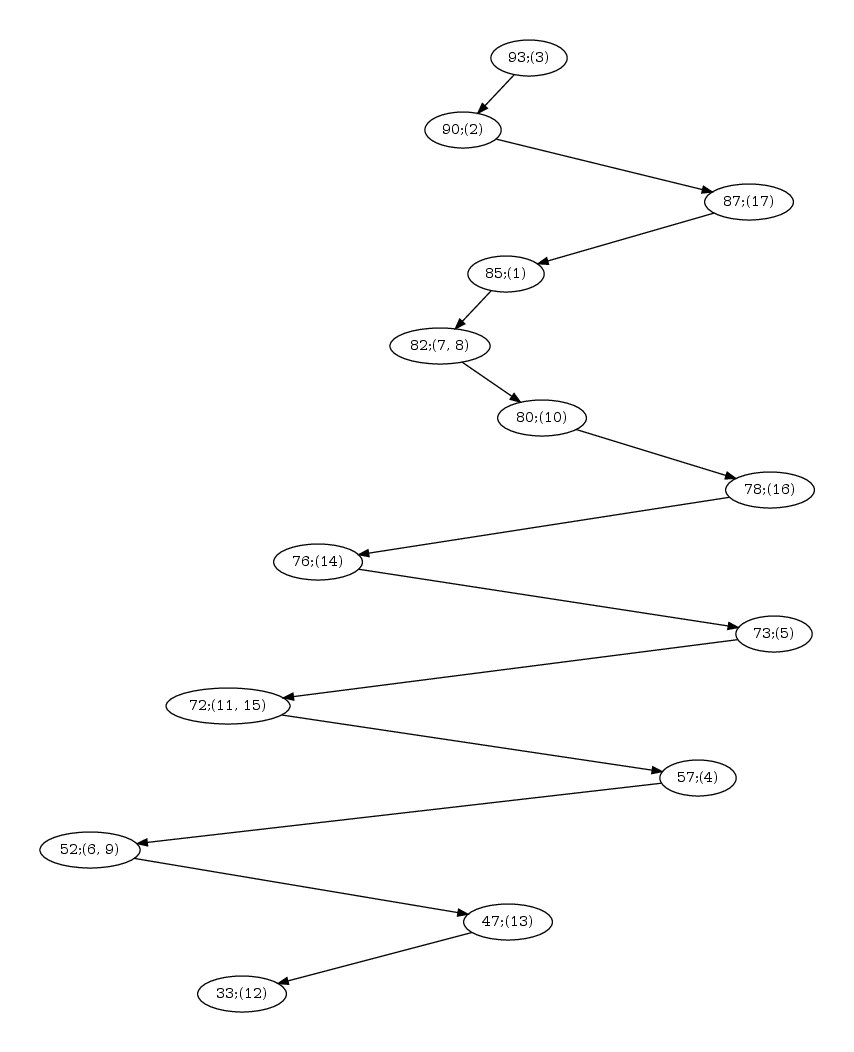 |
| Hasse diagram for the nested-ness of domains in the comparison 1svb vs 1urz. The labels x; (y,z) in a node read as follows: x is the number of residues in the motif; (y,z) are the motif indices, as reported in the persistent_motifs.xml xml file. An arrow between two motifs indicates the inclusion for the corresponding amino acid sets. |
The following comments are in order:
Scatter plot. Fig. fig-rigid-blocks-confs
Hasse diagram. Fig. fig-hasse-confs
As a second illustration, we compare two proteins 1n75 (chain A, 468 residues) and 3afh (chain A, 488 residues).
For these structures, the reference alignment involves 431 a.a., for a lRMSD of 2.05 – yellow lines on Fig. fig-rigid-blocks-chains .
sbl-structural-motifs-chains-kpax.exe --motif-size 30 --lrmsd-threshold 0.8 --allow-incomplete-chains -p 4 --pdb-file pdb/1n75.pdb --chains A --pdb-file pdb/3afh.pdb --chains A --log -d 1n75-3afh
and generate the plots with
sbl-structural-motifs-analyzer.py -d 1n75-3afh
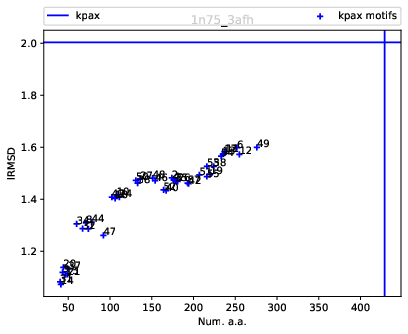 |
| Rigid blocks for 1n75/chain A vs 3afh/chain A: size (number of a.a.) versus lRMSD |
 |
| Hasse diagram for the nested-ness of domains in the comparison of 1n75 vs 3afh. The labels x; (y,z) in a node read as follows: x is the number of residues in the motif; (y,z) are the motif indices, as reported in the persistent_motifs.xml xml file. An arrow between two motifs indicates the inclusion for the corresponding amino acid sets. |
Scatter plot.
Hasse diagram. Fig. fig-hasse-chains
To further investigate each structural motif, the executable outputs PyMol scripts. In order to run the script corresponding to, say motif 8, in the previous run, the user should follow these steps:
load data/1URZ.pdb load data/1SVB.pdb
run results/conformations-sf/sbl-structural-motifs-conformations__block_8_script.py
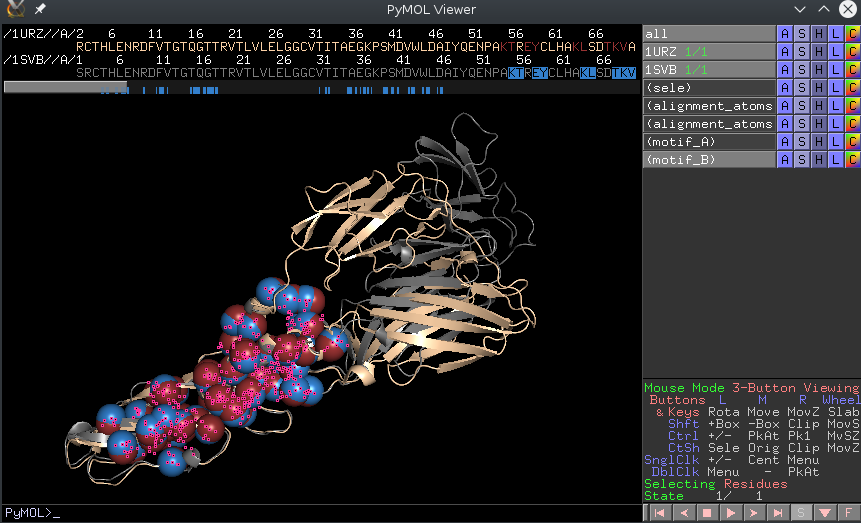 |
| A screenshot of the PyMol window after running one of the outputted pymol scripts |
To be developed.
The package provides two python scripts:
sbl-structural-motifs-computer.py.
Consider a list of four-tuples, namely {(pdbid1, chain1, pdbid2, chain2)}, listed in a text file. The following call uses
sbl-structural-motifs-computer.py -i fatcat2003 -f fatcat2003/fatcat2003--small.txt -a three
sbl-structural-motifs-analyzer.py.
The scatter plots for motifs indicate motif ids, and the associated Hasse diagram (one for each molecule) also indicates how motifs are nested. The following script processes a directory generated by the previous script, and proposes two analysis:
The following call lists the resids found in the motif whose id is 5:
dulfer-fcazals> ./sbl-structural-motifs-analyzer.py -d results/apurva/1CID.pdb-A--2RHE.pdb-A -m 5
Motif file is results/apurva/1CID.pdb-A--2RHE.pdb-A/sbl-structural-motifs-chains-apurva__persistent_motifs.xml
Log file is results/apurva/1CID.pdb-A--2RHE.pdb-A/sbl-structural-motifs-chains-apurva__log.txt
Initial alignment size: 103.0
Initial alignment lRMSD: 3.944686
XML: 1 / 1 files were loaded
('Motif indices:', [1, 2, 3, 4, 5, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18])
('Motif lrmsds:', [1.715135302837146, 3.027206911843852, 2.794978851169716, 3.03162145728718, 1.4790716539949267, 1.7351701619296112, 1.695979267778361, 2.9667660204140045, 3.0269885774433014, 2.689248812159066, 3.031806753459111, 2.739264842927472, 1.6532866267424344, 2.871028387233174, 3.031927685048948, 3.0744944632903914])
('Motif sizes:', [34, 77, 47, 63, 12, 17, 19, 40, 68, 52, 75, 50, 32, 44, 66, 61])
List of the 12 resids in molecule 1 for motif index 5:
[9, 10, 13, 16, 26, 31, 73, 83, 95, 96, 97, 98]
12 resids in molecule 2 for motif index 5:
[14, 15, 18, 21, 32, 37, 73, 83, 97, 98, 99, 100]
dulfer-fcazals>
The following call compares the lists of resids associated with two motif ids – which is especially useful to investigate the relationship between motifs of interest identified on the Hasse diagram of motifs:
dulfer-fcazals> ./sbl-structural-motifs-analyzer.py -d results/apurva/1CID.pdb-A--2RHE.pdb-A -m 5 -n 7
Motif file is results/apurva/1CID.pdb-A--2RHE.pdb-A/sbl-structural-motifs-chains-apurva__persistent_motifs.xml
Log file is results/apurva/1CID.pdb-A--2RHE.pdb-A/sbl-structural-motifs-chains-apurva__log.txt
Initial alignment size: 103.0
Initial alignment lRMSD: 3.944686
XML: 1 / 1 files were loaded
('Motif indices:', [1, 2, 3, 4, 5, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18])
('Motif lrmsds:', [1.715135302837146, 3.027206911843852, 2.794978851169716, 3.03162145728718, 1.4790716539949267, 1.7351701619296112, 1.695979267778361, 2.9667660204140045, 3.0269885774433014, 2.689248812159066, 3.031806753459111, 2.739264842927472, 1.6532866267424344, 2.871028387233174, 3.031927685048948, 3.0744944632903914])
('Motif sizes:', [34, 77, 47, 63, 12, 17, 19, 40, 68, 52, 75, 50, 32, 44, 66, 61])
List of the 12 resids in molecule 1 for motif index 5:
[9, 10, 13, 16, 26, 31, 73, 83, 95, 96, 97, 98]
12 resids in molecule 2 for motif index 5:
[14, 15, 18, 21, 32, 37, 73, 83, 97, 98, 99, 100]
List of the 17 resids in molecule 1 for motif index 7:
[9, 10, 13, 16, 25, 26, 28, 31, 60, 67, 73, 83, 84, 95, 96, 97, 98]
17 resids in molecule 2 for motif index 7:
[14, 15, 18, 21, 31, 32, 34, 37, 59, 66, 73, 83, 84, 97, 98, 99, 100]
[molecule1] Symmetric differences, sizes 0 12 5
Symmetric differences, items:
('A minus B:', [])
('A intersection B:', [9, 10, 13, 16, 26, 31, 73, 83, 95, 96, 97, 98])
('B minus A', [25, 28, 60, 67, 84])
[molecule2] Symmetric differences, sizes 0 12 5
Symmetric differences, items:
('A minus B:', [])
('A intersection B:', [14, 15, 18, 21, 32, 37, 73, 83, 97, 98, 99, 100])
('B minus A', [31, 34, 59, 66, 84])
The implementation is straight-forward: each step described in the previous section is computed in a module, which are all linked together in the following workflow.
The package Structural_motifs uses two novel data structures, the filtration graphs. These were implemented in the classes:

These two classes allow to switch between the different types of filtration.
The package Structural_motifs is centered around two main new modules:
The package also uses the following modules:
T_Structural_motifs_workflow:
See the following jupyter notebook:
Recall that the SBL provides three executables to mine motifs shared by two structures:
The main difference is that for conformations of the same molecule, we do not need to compute any alignment.
In the sequel, we focus on conformations -- using the remaining two executables is similar.
from SBL import Structural_motifs
from Structural_motifs import *
from SBL import SBL_pytools
from SBL_pytools import SBL_pytools as sblpyt
#help(sblpyt)
# Structural motifs general options
smgo = Structural_motifs_general_options()
smgo.update_mode("conformations")
print("General options are: ", str(smgo))
# Prepare the 4-tuple to be processed
smgo.set("input_dir", "fusion-class-II")
data = ("1SVB.pdb", "A", "1URZ.pdb", "A")
# Create an instance of the algo and run it
sm_for_pairs = Structural_motifs_computer_for_pair(smgo)
res_triple = sm_for_pairs.process_two_structures( data )
res_triple.dump()
Socre plot. Recall that the C-alpha ranks are obtained from a structural distance score, namely the distance difference between two C-alpha carbons. If CA_i and CA_j are aligned to CA_i' and CA_j' respectively, the distance difference is s_ij = |d_ij - d_i'j'| where d_ij = |CA_i - CA_j|. We can plot the s_ij scores against their respective C-alpha ranks.
Calpha distance plot. For a given C-alpha rank we can recover the corresponding C-alpha carbons CA_i and CA_j. We can then plot |CA_i - CA_j| (or |CA_i' - CA_j'| for the second structure) against the C-alpha rank. This gives us an indication on how the atoms are selected on the structure. Notice the distinctive sawtooth pattern indicating that atoms can be far apart and we do not necessarily process atoms adjacent to each other on the back-bone.
Sequence shift plot. For the same CA carbons (CA_i and CA_j), we assume their residue sequence numbers are i and j. We can then plot |i - j| (|i' - j'| for the second structure) against the C-alpha ranks. This gives us an indication on their proximity in the sequence. Once again we notice a distinctive sawtooth pattern.
# Extract statistics and run plots
(stats_size_cd, stats_lrmsd_cd) = Structural_motifs_renderer.render_pairwise_comparison_one_aligner(res_triple)




Sticking to our two original structures (conformations of the Tick-Borne Enciphalitis virus envelope protein), we study the incidence of the filtration on the results. To this end, we re-run the previsous calculations passing with the --use-sfd-filtration option.
from SBL import Structural_motifs
from Structural_motifs import *
from SBL import SBL_pytools
from SBL_pytools import SBL_pytools as sblpyt
#help(sblpyt)
# Structural motifs general options
smgo = Structural_motifs_general_options()
smgo.update_mode("conformations")
smgo.set("use_sfd", True) # Use space filling diagram instead of conserved distances
# Prepare the 4-tuple to be processed
smgo.set("input_dir", "fusion-class-II")
data = ("1SVB.pdb", "A", "1URZ.pdb", "A")
# Create an instance of the algo and run it
sm_for_pairs = Structural_motifs_computer_for_pair(smgo)
res_triple = sm_for_pairs.process_two_structures( data )
res_triple.dump()
# Stats and plots
(stats_size_sfd, stats_lrmsd_sfd) = Structural_motifs_renderer.render_pairwise_comparison_one_aligner(res_triple)

We can then proceed to compute pareto envelopes and plot the stats for both methods on the same figure.
def compute_pareto_envelope(lrmsd_stats, size_stats):
#create motif points
motif_points = [[lrmsd_stats[i], size_stats[i]] for i in range(0, len(lrmsd_stats))]
#sort motifs by increasing lRMSD
motif_points = sorted(motif_points, key=lambda motifs: motifs[0])
#find dominated points
dominated_points = []
for i in range(0, len(motif_points)):
for j in range(i+1, len(motif_points)):
if(motif_points[i][1] >= motif_points[j][1]):
dominated_points.append(motif_points[j])
#exclude them from the pareto envelope
pareto_envelope = list(zip(*[motif for motif in motif_points if (motif not in dominated_points)]))
motif_points = list(zip(*motif_points))
# just for plotting purposes (so the limits are will defined)
min_lrmsd = min(pareto_envelope[0])
pareto_envelope[0] = [min_lrmsd] + list(pareto_envelope[0])
pareto_envelope[1] = [0] + list(pareto_envelope[1])
return motif_points, pareto_envelope
def pareto(cd_lrmsd_stats, cd_size_stats, sfd_lrmsd_stats, sfd_size_stats):
#just to define the bounds of the pareto envelope (for esthetic purposes)
max_lrmsd = max(max(cd_lrmsd_stats), max(sfd_lrmsd_stats))
max_size = max(max(cd_size_stats), max(sfd_size_stats))
cd_motif_points, cd_pareto_env = compute_pareto_envelope(cd_lrmsd_stats, cd_size_stats)
sfd_motif_points, sfd_pareto_env = compute_pareto_envelope(sfd_lrmsd_stats, sfd_size_stats)
cd_pareto_env[0].append(max_lrmsd+5)
cd_pareto_env[1].append(max(cd_pareto_env[1]))
sfd_pareto_env[0].append(max_lrmsd+5)
sfd_pareto_env[1].append(max(sfd_pareto_env[1]))
plt.plot(cd_pareto_env[0], cd_pareto_env[1])
plt.scatter(cd_motif_points[0], cd_motif_points[1])
plt.plot(sfd_pareto_env[0], sfd_pareto_env[1], color='red')
plt.scatter(sfd_motif_points[0], sfd_motif_points[1], color='red')
plt.xlabel('lRMSD')
plt.ylabel('Size')
plt.show()
pareto(stats_lrmsd_cd, stats_size_cd, stats_lrmsd_sfd, stats_size_sfd)
print("Done")

The executable also outputs a number of PyMol script to view motifs directly. Each motifs has a unique identifier and the scripts follow the same nomenclature: to view motif 31 look for the '_block_31_script.py' file.
To run the script from PyMol simply load the two structures and type 'run name_of_the_script.py' Below is the image of two motifs yielded from the previous comparisons. As you can see our method allows to recover the blocks which are invariant in the conformational changes.
from IPython.display import Image
display(Image(filename ="fig/motif_51.png", width=500, height=500));
display(Image(filename ="fig/motif_54.png", width=500, height=500));

