|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
![]()
Authors: F. Cazals and A. Chevallier and T. Dreyfus and C. Le Breton
The description of molecular systems encompasses several aspects (geometry, topology, biophysics), see SBL: terminology and concepts. This package solely handles the topology of biomolecules.
The covalent structure (CS) of a protein is a graph, possibly with several connected components. The CS is created and then edited. Ultimately, a mapping between the topology and geometry (embedding) is realized.
Creating the CS data structure.
The CS data structure is represented as a boost subgraph. Such a graph contains vertices and edges. Each vertex (containing the information about a particle) is accessed via a so-called particle representation (particle rep for short), and an edge (modeling a covalent bond) via a bond representation or a pair of particle reps.
The CS of a protein is built upon the amino acid sequence of all chains provided in the input file.
In both cases, a post-processing step is performed to check that consecutive a.a. in the sequence specification are consecutive by ensuring that the resids are so.
Missing amino acids (aka gaps) are allowed via the SBL::IO::T_Molecular_covalent_structure_loader::set_allow_incomplete_chains(bool) method. In that case, the number of connected components of the chain is 1 plus the number of gaps.
Editing the CS data structure.
Once created the CS undergoes the following editing steps:
SS bonds can also be found geometrically, using the SBL::IO::T_Molecular_covalent_structure_loader::set_ss_bond_search(bool) method. This inference step computes the distances between pairs of S atoms using their coordinates in the PDB/mmCIF file.
Creating maps.
The following maps are then set to make it possible to connect the molecular graph with coordinates. Atom ids (aka atom serial numbers) may not be consecutive. To ease the processing, we define a consecutive version of atomids as follows:
The maps of interest are created in two steps:
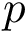 ; then, map to the sorted_atom_serial_number_index
; then, map to the sorted_atom_serial_number_indexAccessors.
As a graph, the CS can be accessed and visited using iterators. Broadly, there are two main settings:
Atoms and embedded atoms.
As said above, the covalent structure represents the graph of a molecular system. For example, for a polypeptide chain, this graph links the amino acids together. However, in a classical structure obtained by say X ray crystallography, selected atoms may be missing – e.g. hydrogen atoms or atoms located in flexible regions. Such are atoms are found in the covalent structure, but their geometry is not accessible. They are termed un-embedded. More detailed are provided below for the construction of a covalent structure for proteins.
Default and optimized.
When the covalent structure is used to compute the potential energy and the gradient of the energy of a large number of conformations, it becomes necessary to optimize its traversal – and the calculation of internal coordinates. The base data structure uses a graph for representing it, so that it is easy to visit particles and bonds. However, the following comments are in order:
For these reasons, two covalent data structures are provided:
The case of other biopolymers (DNA, RNA) is similar to that of proteins, except that one connects bases instead of amino-acids. However, the construction of such biopolymers is currently not supported.
The first implementation provided uses internally a graph data structure to code particles and bonds, which comes with the following pros and cons:
Three important data structures are provided by this package :
This concept is used to represent a particle in the covalent structure and to attach information to it.
Depending on the context, the relevant information and the necessary operations on a particle vary.
For example, the particle could belong to a small molecule or to a polypeptidic chain.
In this latter case, one may want to retrieve a particular atom (e.g. the Calpha carbon) – an irrelevant request if the molecule is not a polypeptide chain.
For this reason, the class SBL::CSB::T_Particle_info_traits< ParticleInfo > provides all the necessary types and operations depending on the model of ParticleInfo . Such a mechanism uses the C++ Partial Template Specialization : any structure can be used as a model of the concept ParticleInfo provided that the class SBL::CSB::T_Particle_info_traits is redefined for this particular model. The required operations depend on the context where it is used :
For any covalent structure, the requirements are given by the class SBL::CSB::T_Molecular_covalent_structure : SBL::CSB::T_Particle_info_traits , which must define two operators:
Less : comparator used to retrieve a vertex in the covalent structure from its info.
Printer : prints the information of the particle into a stream passed as argument.
For proteins, the requirements are given by the classes SBL::CSB::T_Molecular_covalent_structure_builder_for_proteins and SBL::IO::T_Molecular_covalent_structure_loader : SBL::CSB::T_Particle_info_traits must define three operators:
Finder : uses the covalent structure and biochemical data identifying a particle (chain identifier, residue sequence number, insertion code, atom name) to retrieve the corresponding vertex in the covalent structure;
Builder : builds an info from the relevant biochemical data (chain identifier, residue sequence number, insertion code, atom name, or a Molecular_system atom having all this data) and a terminal tag (positive if N-terminal, negative if C-terminal, null otherwise);
Aliases implements a dictionnary of aliases for the atom names in a protein, in order to have a unique atomic naming convention – see atom-naming-convention;
Two models of ParticleInfo are provided :
comparable: this ensures that each instance of ParticleInfo uniquely identifies a particle;
streamable: this ensures that each particle in the covalent structure has an associated name, which is e.g. used when printing the covalent structure as a graph using Graphviz .
Basically, the class SBL::CSB::T_Molecular_covalent_structure is a wrapper for a boost graph with accessors, modifiers and iterators over the graph. More precisely, it uses the boost subgraph data structure to offer the possibility of clustering the covalent structure, e.g by polypeptidic chains or by residues. There is a unique template parameter ParticleInfo representing the information attached to a particle, that is a simple string by default. An object of type ParticleInfo should be ordered, streamable and default constructible. Four main functionnality are available.
Building the covalent structure.
Adding a particle to the covalent structure is done using the method SBL::CSB::T_Molecular_covalent_structure::add_particle : this method takes a particle info representing that particle.
Adding a bond is done using the method SBL::CSB::T_Molecular_covalent_structure::add_bond : this method takes two vertices of the graph, and adds, if possible, an edge between the two vertices. It also takes optionnaly a bond type (simple by default, or double) to represent the covalence of the bond.
Establishing a correspondence with an embedded geometry specified by cartesian coordinates.
It is possible to map a geometric model over the covalent structure by simply mapping the vertices of the graph to the geometric representation of the particles.
The notion of partial embedding is especially important when loading polypeptide chains from PDB/mmCIF files, which in general do not contain coordinates for all atoms (hydrogen atoms, heavy atoms located in flexible regions).
In the SBL, a geometric model is represented by a conformation that is a D-dimensional point consisting of the cartesian coordinates of the particles of a molecule. By default, the ith inserted vertex is mapped to the ith particle in the conformation.
Given an embedded vertex, it is then possible to access x, y and z coordinates from the covalent structure from the methods SBL::CSB::T_Molecular_covalent_structure::get_x, SBL::CSB::T_Molecular_covalent_structure::get_y and SBL::CSB::T_Molecular_covalent_structure::get_z .
Iterating over the covalent structure.
It is possible to iterate over the particles, bonds, bond angles and torsion angles of the covalent structure. There are two modes of iteration : over all the entities, or over all the entities that are mapped with a geometric model. For example, if ones want to compute internal coordinates, it is only possible to do so from particles that are mapped. To switch between the modes, each iteration method has as argument an optional boolean tag (by default, it iterates over mapped particles).
Consider a set of particles associated with one or several connected components of the covalent structure. The subgraph induced by these particles is returned by SBL::CSB::T_Molecular_covalent_structure::get_sub_structure . The type of this graph is SBL::CSB::T_Molecular_covalent_structure . Note that stored information are not duplicated : modifying the sub-structure modifies also the parent covalent structure, and modifying the parent covalent structure modifies the sub-structure.
As an application, one can iterate on the individual molecules of a molecular system, as these correspond to the connected components of the covalent structure. To do so, one proceeds as follows :
(i) find the molecules using the method SBL::CSB::T_Molecular_covalent_structure::get_molecules which fills a container of particles, with one particle for each molecule;
(ii) for each found particle, create the subgraph containing that particle using the method SBL::CSB::T_Molecular_covalent_structure::get_molecule;
Displaying the covalent structure.
The covalent structure can be dumped in a file using Graphviz through the method SBL::CSB::T_Molecular_covalent_structure::print . For large systems (e.g. large proteins), the high number of particles, the Graphviz software may take a time to create the output. Also note that the neato command from Graphviz has a better rendering than the more classical dot command in this case.
Building a covalent structure requires three pieces of information:
Attributes for vertices (type of vertices).
Attributes for edges (type of covalent bonds).
The topology itself. For example, when building the subgraph associated with an amino-acid, the topology of this amino-acid is required. this information can be implicit as in the case of amnino-acids and polypeptide chains, or can be explicit i.e. provided in the input file. This accounts for the two types of builders provided thereafter.
Implicit builders for polypeptide chains. The class SBL::CSB::T_Molecular_covalent_structure_builder_for_proteins is a functor building the covalent structure from an arbitrary data structure SBL::CSB::T_Molecular_covalent_structure_builder_for_proteins::Structure defining the polypeptidic chains and their residues. More precisely, a protein is represented by a mapping from a chain identifier to the chain itself, each chain being represented by a list of pairs (residue name, residue id). The graph of the covalent structure can be constructed at different scales : (0) with all atoms from all residues, (1) with only the heavy atoms, (2) with only the carbon alpha of each residue, or (3) with pseudo-atoms from the Martini coarse grain model. The scale factor is determined at the construction of the builder and is 0 by default. The only template parameter Covalentstructure is the covalent structure type.
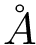 . If it is not the case, no bond is created in the covalent structure and the covalent structure has multiple connected components.
. If it is not the case, no bond is created in the covalent structure and the covalent structure has multiple connected components.
Explicit builder for other molecules.
Since there is no particular difficulty nor operation for loading molecules from the MOL format, building the covalent structure from a MOL file is directly done in the loader SBL::CSB::T_Molecular_covalent_structure_loader_from_MOL .
Practically, the following file formats are used:
The (legacy) PDB format: the reference format for biomolecules whose structure has been resolved and are deposited in the Protein Data Bank ( PDB website).
The mmCIF file format.
As noted above, loaders for CS depend on loaders for molecular systems from the package Molecular_system. Such loaders use the libcifpp library.
Loader from PDB/mmCIF files.
The class SBL::IO::T_Molecular_covalent_structure_loader is a loader as defined in the Module_base package : it loads an input PDB/mmCIF, uses a builder to build a covalent structure, and maps the vertices of the covalent structure to the loaded atoms by order of their atomic sequence identifier.
The following comments are in order:
Water molecules are not loaded by default. To change this behaviour, one can use the methods SBL::IO::T_Molecular_covalent_structure_loader::set_loaded_water. Then, water molecules are added as independent connected components in the covalent structure graph.
Hetero atoms are not loaded by default. In the future, the flag SBL::IO::T_Molecular_covalent_structure_loader::set_loaded_hetatoms will be used to load them. Note that for hetero atoms which are not monoatomic ions, the connectivity is unknown.
As note above, disulfide bonds are added to the built covalent structure, see the package Pointwise_interactions. This feature is available by default but can be turned off using the method SBL::IO::T_Molecular_covalent_structure_loader::set_without_disulfide_bonds .
It is possible to change the maximal authorized length of the bond between the C of a residue and the N of the next residue using the method SBL::IO::T_Molecular_covalent_structure_loader::set_max_bond_distance.
Specific atomic naming conventions.
Loader from MOL files.
The class SBL::IO::T_Molecular_covalent_structure_loader_from_MOL is a loader as defined in the Module_base package : it simply loads an input MOL file, and directly builds the covalent structure from the loaded data and maps the vertices to the laoded particles. It has a unique template parameter MolecularCovalentStructure , that is the representation of the covalent structure, by default SBL::CSB::T_Molecular_covalent_structure <> (see package Molecular_covalent_structure)
It is possible to set the coarse level used by the builder to create the covalent structure. This class has four template parameters, all having a default type :
MolecularCovalentStructure : representation of the covalent structure, by default SBL::CSB::T_Molecular_covalent_structure <> (the parameter ParticleInfo is by default a simple string, see package Molecular_covalent_structure)
MolecularCovalentStructureBuilder : builder of the covalent structure, by default SBL::CSB::T_Molecular_covalent_structure_builder_for_proteins < MolecularCovalentStructure >,
Manipulating molecular coordinates (package Molecular_coordinates) or computing potential energies (package Molecular_potential_energy) benefits from a canonical representation of internal coordinates.
The method SBL::CSB::T_Molecular_covalent_structure::get_canonical_rep returns the cannonized representation of a bond, a bond angle or a dihedral angle.
Canonical representation of a bond. Such a representation is obtained by ordering its two vertices – that is the particle_rep used to represent the vertices.
Canonical representation of a valence angle. Such a representation is obtained by ordering the first and third vertices – since the middle one is imposed.
Canonical representation of a dihedral angle. This case covers two sub-cases (see also the package Molecular_coordinates):
The class SBL::CSB::T_Molecular_covalent_structure_optimal< ParticleInfo > is an optimized version of the covalent structure data structure. In particular, all entities (particles, bonds and angles) that are used in the computation of the energy are stored in a vector, ensuring a constant time access each time.
In order to use this class, once has to first build a covalent structure with the class SBL::CSB::T_Molecular_covalent_structure, then use the class SBL::CSB::T_Molecular_potential_energy_structure_parameters_traits_optimal to build the optimized version of the covalent structure data structure. See the package Molecular_potential_energy for examples and more details.
The following example shows how to load a PDB file and build the corresponding covalent structure at a given scale. It then output a dot file in the Graphviz format to check the covalent structure.