We provide a generic framework for clustering algorithms, together with specific implementations corresponding to various algorithms, namely
k-means. Given a pre-defined number of centers k, k-means partitions the input datasets into clusters – one per center, so as to minimize the sum of squared distances of samples to their nearest center. We provide in particular the smart seeding procedure from [12] .
Tomato. Tomato is a clustering algorithm defining clusters from local maxima of an estimated density. The method uses topological persistence to identify the most significant clusters, as detailed in [52] .
Implementation
Terminology
Consider a dataset consisting of observations (data points or points for short). A clustering is a partition of the input dataset into disjoint subsets called clusters.
We represent clusters as follows:
We use the following cluster representation: the clustering of points into clusters is specified by mapping each point to an integer in the range .
A partial clustering is a collection of clusters whose union is strictly contained in the input dataset (e.g. some outliers have been removed).
Design
The package is designed around the module class SBL::Modules::T_Cluster_engine_module : while each engine is implemented in its own base file, the need of a common design for each engine is necessary for using a general cluster module. The two main engines are:
K-means, implemented by SBL::GT::T_Cluster_engine_k_means< PointType , VectorType , Distance > ; The parameter PointType is a representation of a geometric point, while the parameter VectorType is a representation of a geometric vector supporting operations like addition and division; the parameter Distance is a functor computing the distance between two points; the CGAL library naturally offers all these types, e.g using the class CGAL::Cartesian_d;
Morse theory based algorithm (see package Morse_theory_based_analyzer for details), implemented by SBL::GT::T_Cluster_engine_Morse_theory_based< PointType , Distance , TNNQuery , TGetDensity > ; The parameters PointType and Distance have the exact same sense as previously mentionned; the parameter TNNQuery is the spatial search engine used for building the nearest neighbors graph (NNG); the parameter TNNQuery is a template itself parametrized by a distance functor computing distances between vertices of NNG (this distance data structure is internal to the clustering engine); finally, the parameter TGetDensity is a functor computing the density of a vertex in the NNG; it is also a template parametrized by the type of NNG (which is defined internally to the clustering engine);
Using these classes is especially easy, via the template class SBL::GT::T_Cluster_engine_workflow.
Functionnality
Generic input: a file containing points, complying with the Point_d concept (a line list the dimension and then the number of coordinates).
Generic output: a text file giving for each point, the index of its clusters (0..n-1 convention).
Visualization: we also provide a script displaying the clusters.
Examples
The following examples show how to use the K-means algorithm with the different selectors, and how to use the provided module.
Using k-means
This example loads an input set of points and computes 4 clusters using k-means algorithm using the random strategy for selecting the initial centers of mass.
Using Morse theory based strategy
This example loads an input set of points and computes 4 clusters using k-means algorithm using the random strategy for selecting the initial centers of mass.
Using the module
This example loads an input set of points and instantiates the K-means module for computing an input number of clusters using the default (random) strategy for selecting the initial centers of mass.
Applications
Programs
This package offers programs for computing a clustering of a set of points:
the Morse theory based strategy: sbl-cluster-MTB-euclid.exe
Note that a given executable is qualified by (i) a space and the associated distance, and (ii) a method (k-means or Morse theory based).
Using the aforementioned workflow mechanism, adding new variations is especially easy.
k-means: main specifications
sbl-cluster-k-means-euclid.exe : a program comparing two sets of D-dimensional points using the Euclidean metric and k-means algorithm. Note that the input is a text file listing the points in the Point_d format (dimension followed by coordinates).
Main options. The main options are:
–points-filestring: Input points with the d-dimensional point format -k-means-kstring: Number of clusters –k-means-selectorstring: k-means strategy i.e. / random (default) / plusplus / minimax –k-means-itermax string: Maximum number of iterations
Input. The main input consist of the data points and the number of clusters.
Main output. The main files reported are:
Log file, txt format, suffix __log.txt : main log file
Centers file, point_d format, suffix __centers.txt : coordinates in point_d format of the centers
Clusters file, txt format, suffix __clusters.txt : an ordered text file with on each line the index of the cluster the corresponding points belongs to.
Comments.
k-means minimizes, within each cluster, the sum of squared distances. In doing so, one uses the centroid of each cluster. Note that the centroid is distinct from the point minimizing the sum of distances to sample points, known as the Fermat–Weber point or geometric median, a problem still under scrutiny [59] . The variation of k-means using the median instead of the centroid is known as k-medians.
Tomato: main specifications
sbl-cluster-MTB-euclid.exe : a program comparing two sets of D-dimensional points using Euclidean metric and the package Morse_theory_based_analyzer.
Main options. The main options are as follows:
–points-filestring: Input points with the d-dimensional point format –num-neighborsstring: Number of neighbors used to define the nearest neighbor graph –persistence-thresholdstring: Threshold used to define local maxima whence clusters
Input. The main input is the point set in Point_d format (dimension followed by coordinates).
Main output.
First, one finds the same files as for k-means:
Log file, txt format, suffix __log.txt : main log file
Centers file, point_d format, suffix __centers.txt : coordinates in point_d format of the centers
Clusters file, txt format, suffix __clusters.txt : an ordered text file with on each line the index of the cluster the corresponding points belongs to.
Second, one finds the persistence diagram i.e. the coordinates of critical points:
Persistence diagram, txt format, suffix__persistence_diagram.txt: coordinates of points defining the persistence diagram.
Finally, one finds the bipartite graph connecting local maximma and associated saddle points – this graph is known as the Morse-Smale-Witten chain complex:
Tomato performs an analysis of the density estimate by sweeping the height function provided by the density estimate, from top top bottom. A local maximum dies when it merges with another local maximum, upon encountering a pass (an index d-1 saddle) connecting them. Consequently, the death date of a local maximum is less than its birth date. This explains points on the persistence diagram are located below the diagonal y=x. We note that Tomato is a simplified version of programs provided by the package Morse_theory_based_analyzer. For a more complete analysis of a cloud of points, please use the package Morse_theory_based_analyzer.
Visualization of clusters in 2D
In two dimensions, one can plot clusters with the script sbl-clusters-display.py.
For the first and second examples above, generated by kmeans (with random or ++ initialization):
Marker : Calculation Started
Using executable /user/fcazals/home/projects/proj-soft/sbl-install/bin/sbl-cluster-MTB-euclid.exe
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d2.txt --num-neighbors 8 --persistence-threshold 0.010000
All output files: ['sbl-cluster-MTB-euclid__centers.txt\n', 'sbl-cluster-MTB-euclid__clusters.txt\n', 'sbl-cluster-MTB-euclid__log.txt\n', 'sbl-cluster-MTB-euclid__msw_edges.txt\n', 'sbl-cluster-MTB-euclid__msw_points.txt\n', 'sbl-cluster-MTB-euclid__msw_weights.txt\n', 'sbl-cluster-MTB-euclid__persistence_diagram.txt\n']
Log file is: tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__log.txt
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d2.txt --num-neighbors 8 --persistence-threshold 0.010000
D-points Loader
Statistics:
Number of loaded data: 1
-- Number of loaded points in ensemble: 500
Cluster Engine
Statistics:
-- Number of clusters : 5
-- Size of clusters : (0, 16) (1, 463) (2, 18) (3, 2) (4, 1)
Report...
End Run
General Statistics:
Times elapsed for computations (in seconds):
-- Cluster Engine: 0.037940
Total: 0.037940
Display command /user/fcazals/home/projects/proj-soft/sbl-install/scripts/sbl-clusters-display.py -f data/points-N100-d2.txt -c tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__clusters.txt -C tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__centers.txt -p tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__persistence_diagram.txt -o tmp-results-MTB-euclid
Marker : Calculation Ended
Marker : Calculation Started
Using executable /user/fcazals/home/projects/proj-soft/sbl-install/bin/sbl-cluster-MTB-euclid.exe
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d4.txt --num-neighbors 8 --persistence-threshold 0.010000
All output files: ['points-N100-d2--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d2--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'sbl-cluster-MTB-euclid__centers.txt\n', 'sbl-cluster-MTB-euclid__clusters.txt\n', 'sbl-cluster-MTB-euclid__log.txt\n', 'sbl-cluster-MTB-euclid__msw_edges.txt\n', 'sbl-cluster-MTB-euclid__msw_points.txt\n', 'sbl-cluster-MTB-euclid__msw_weights.txt\n', 'sbl-cluster-MTB-euclid__persistence_diagram.txt\n']
Log file is: tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__log.txt
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d4.txt --num-neighbors 8 --persistence-threshold 0.010000
D-points Loader
Statistics:
Number of loaded data: 1
-- Number of loaded points in ensemble: 500
Cluster Engine
Statistics:
-- Number of clusters : 5
-- Size of clusters : (0, 487) (1, 10) (2, 1) (3, 1) (4, 1)
Report...
End Run
General Statistics:
Times elapsed for computations (in seconds):
-- Cluster Engine: 0.032958
Total: 0.032958
Display command /user/fcazals/home/projects/proj-soft/sbl-install/scripts/sbl-clusters-display.py -f data/points-N100-d4.txt -c tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__clusters.txt -C tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__centers.txt -p tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__persistence_diagram.txt -o tmp-results-MTB-euclid
Marker : Calculation Ended
Marker : Calculation Started
Using executable /user/fcazals/home/projects/proj-soft/sbl-install/bin/sbl-cluster-MTB-euclid.exe
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d6.txt --num-neighbors 8 --persistence-threshold 0.010000
All output files: ['points-N100-d2--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d2--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'points-N100-d4--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d4--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'sbl-cluster-MTB-euclid__centers.txt\n', 'sbl-cluster-MTB-euclid__clusters.txt\n', 'sbl-cluster-MTB-euclid__log.txt\n', 'sbl-cluster-MTB-euclid__msw_edges.txt\n', 'sbl-cluster-MTB-euclid__msw_points.txt\n', 'sbl-cluster-MTB-euclid__msw_weights.txt\n', 'sbl-cluster-MTB-euclid__persistence_diagram.txt\n']
Log file is: tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__log.txt
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N100-d6.txt --num-neighbors 8 --persistence-threshold 0.010000
D-points Loader
Statistics:
Number of loaded data: 1
-- Number of loaded points in ensemble: 500
Cluster Engine
Statistics:
-- Number of clusters : 4
-- Size of clusters : (0, 497) (1, 1) (2, 1) (3, 1)
Report...
End Run
General Statistics:
Times elapsed for computations (in seconds):
-- Cluster Engine: 0.032477
Total: 0.032477
Display command /user/fcazals/home/projects/proj-soft/sbl-install/scripts/sbl-clusters-display.py -f data/points-N100-d6.txt -c tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__clusters.txt -C tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__centers.txt -p tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__persistence_diagram.txt -o tmp-results-MTB-euclid
Marker : Calculation Ended
Marker : Calculation Started
Using executable /user/fcazals/home/projects/proj-soft/sbl-install/bin/sbl-cluster-MTB-euclid.exe
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N200-d50.txt --num-neighbors 8 --persistence-threshold 0.010000
All output files: ['points-N100-d2--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d2--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'points-N100-d4--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d4--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'points-N100-d6--sbl-cluster-MTB-euclid__clusters--persistences.png\n', 'points-N100-d6--sbl-cluster-MTB-euclid__clusters--sbl-cluster-MTB-euclid__centers.png\n', 'sbl-cluster-MTB-euclid__centers.txt\n', 'sbl-cluster-MTB-euclid__clusters.txt\n', 'sbl-cluster-MTB-euclid__log.txt\n', 'sbl-cluster-MTB-euclid__msw_edges.txt\n', 'sbl-cluster-MTB-euclid__msw_points.txt\n', 'sbl-cluster-MTB-euclid__msw_weights.txt\n', 'sbl-cluster-MTB-euclid__persistence_diagram.txt\n']
Log file is: tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__log.txt
Running: sbl-cluster-MTB-euclid.exe -v -l -d tmp-results-MTB-euclid --points-file data/points-N200-d50.txt --num-neighbors 8 --persistence-threshold 0.010000
D-points Loader
Statistics:
Number of loaded data: 1
-- Number of loaded points in ensemble: 1000
Cluster Engine
Statistics:
-- Number of clusters : 15
-- Size of clusters : (0, 193) (1, 199) (2, 192) (3, 400) (4, 3) (5, 2) (6, 2) (7, 2) (8, 1) (9, 1) (10, 1) (11, 1) (12, 1) (13, 1) (14, 1)
Report...
End Run
General Statistics:
Times elapsed for computations (in seconds):
-- Cluster Engine: 0.068028
Total: 0.068028
Display command /user/fcazals/home/projects/proj-soft/sbl-install/scripts/sbl-clusters-display.py -f data/points-N200-d50.txt -c tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__clusters.txt -C tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__centers.txt -p tmp-results-MTB-euclid/sbl-cluster-MTB-euclid__persistence_diagram.txt -o tmp-results-MTB-euclid
Marker : Calculation Ended
Let us display the clusters together with the persistence diagrams (PD)¶
For PD, note that points are below the diagoal: one cluster is defined as a mode of the dentisy estimated associated with
the point cloud, so that we study the stable super-level sets of this estimated density.
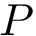 consisting of
consisting of 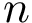 observations (data points or points for short). A clustering is a partition of the input dataset into disjoint subsets called clusters.
observations (data points or points for short). A clustering is a partition of the input dataset into disjoint subsets called clusters. 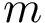 clusters is specified by mapping each point to an integer in the range
clusters is specified by mapping each point to an integer in the range 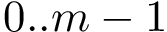 .
. 

