|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
|
Structural Bioinformatics Library
Template C++ / Python API for developping structural bioinformatics applications.
|
Authors: F. Cazals and T. Dreyfus
![]()
A typical computer experiment consists of rounds, including:
The current package provides a solution to handle these two steps, using the notion of batch:
These notions are defined below.
The whole package is written using Python.
Section Pre-requisites discusses the different objects manipulated, and in particular so-called batches. Section Input: Dataset and Run Specifications specifies the way batches are created. Finally, section Output: Runs of Batches explain how to run batches.
We define sequentially the notions required to use the batch manager:
Dataset. A dataset is a coherent collection of files, meant for processing by a given program, say P.exe in the sequel.
A dataset is identified by the directory containing it.
Database. A database is a list of datasets. There are two ways to list the entries contained within a database:
We wish to run the program P.exe on a dataset. Also assume that P.exe has a number of command-line options, complying with the following usual conventions:
Run specification tuples. A run specification tuple also called tuple for short is a set of options fully specifying one execution of P.exe. The tuple is represented as a list of name-value-pair: the name stands for the option, and the value for the argument. When the option does not require any argument, its value is the empty string.
For example: (f, 1vfb.pdb) stands for -f 1vfb.pdb, (number, 15) stands for –number 15, (verbose, ""), stands for –verbose , etc.
A run specification ensemble is a list of run specification tuples. The package provides two ways to generate such ensembles:
When the argument of an option is an input file, the option is termed an Input File Option (IFO). The number of IFO of a program determines its arity .
Specifying an IFO requires three ingredients: (i) the name of the option, (ii) a dataset containing the possible input files of the option, and (iii) a rule specifying how to generate the name-value-pairs of IFO within a run.
For the sequel, we wish to stress the following:
Simple IFO declaration. The IFO are specified in a run specification file formally defined below, with the keyword IFO followed by the option name and possibly a regular expression characterizing the input file names for this option. In the following example, one declares two input files with the option names file-1 and file-2 , the input files being any text file for the former and any PDB file for the latter:
IFO file-1 ".*.txt" IFO file-2 ".*.pdb"
Tuple IFO declaration. In using say two simple IFO declaration, both input files are totally independent, that is, there is an association rule between them. Sometimes, one wishes to group input files, for example by pairs of files with a common prefix. This is possible by specifying tuples of IFO :
IFO (file-1, file-2) "common regex" ("regex_1", "regex_2")
In this case, pairs of input files are filtered such that both files match the common regular expression exactly in the same way, and each file is further specified by its particular regular expression. Note that the regular expressions have to be enough specific : if there is an ambiguity on how several files should be associated within a tuple, an error is returned.
Specification: Dataset. Specified by the name of the directory defining the dataset.
Specification: Name-value-pairs. There are five types of rules to specify the name-value-pairs. We illustrate each of them with an example;
IFO-ASSOC-RULE none
IFO-ASSOC-RULE unary
Case 1: for a simple IFO declaration: the unary rule states that a single file is used as input.
Case 2: for a tuple IFO declaration: the unary rule states that a unique/single tuple of input files is used as input.
IFO-ASSOC-RULE cartesian-product <arity>
IFO-ASSOC-RULE combinatorial <arity>
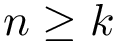 cases are generated. Note that since the order does not matter, the k IFO declarations must be consistent. To enforce this, the user is forced to use a single IFO declaration (simple or tuple).
cases are generated. Note that since the order does not matter, the k IFO declarations must be consistent. To enforce this, the user is forced to use a single IFO declaration (simple or tuple).IFO restrictions. When using the cartesian-product rule, one would like to form only a subset of tuples of input files. For example, only files starting with the same keyword should form a tuple of input files for a given run. To do so, one can use the IFO-REGEX specification:
IFO-REGEX "regex"
This additional specification will constrain all input files of a given run to match identically the input regular expression.
When the argument of an option is not an input file, the option is termed a Non-input File Option (NFO). The following examples illustrate the three ways to declare a NFO:
NFO verbose
NFO prefix alice bob
NFO (numvertices, numedges) (10, 9) (100, 99) (1000, 999)
Note that the last two options yield a list of values. If several NFO options are declared, the cartesian product of these lists is taken, therefore defining the list of possible combinations of NFO.
A run specification file is a file specifying the IFO and NFO options just discussed. Each command line of the specification file starts with a keyword, and there are four such keywords:
Example run specification files are given in the section Examples
As defined in Introduction, a batch is a set of coherent executions, as specified in the run specification file.
If these executions involve a dataset, the files in the dataset are used to fill input file options values using the association rules specified in the run specification file.
More precisely, given a dataset and a run specification file, a run specification ensemble is constructed as follows:
A batch yields an output directory containing the output file, the directory name being automatically inferred. A default output directory name is given as the name of the program without extension followed by the name of the directory of the dataset. For example, if on wants to run the program P.exe with the dataset data , the name of the output directory will be P-data .
In fact, when running a batch, the output directory is created, and the program is run from this output directory.
A batch can be split into smaller batches, in four ways:
When splitting a batch, each resulting batch has its own output directory: the name of the output directory of a split batch is the one of the parent batch, followed by the name-value-pairs of the invariant options. See section Coupling Data Generation and Processing with two Specification Files for an example.
Creating a batch requires two inputs:
batch.load_dataset("input-data", ".*.pdb", False)
batch.load_run_specification("run-specification.txt")
Once a batch is created and associated to a dataset and a run specification ensemble, one can run the batch, i.e running all the executions listed in the run specification ensemble. This is done using the method SBL::Batch_manager::BM_Batch::run :
batch.run()
If it does not exist, the output directory is created and will be filled with the output of the different execution. The method SBL::Batch_manager::BM_Batch::print_batch dumps into the console the list of command line executions, without running them:
batch.print_batch()
The method SBL::Batch_manager::BM_Batch::get_lists_of_run_options returns the lists of options for each run in the batch as name-value pairs when a value is specified, and as a simple name when there is no value associated to the option:
nvps = batch.get_lists_of_run_options()
It is also possible to run the batch such that each execution is repeated a number of time. This feature is of special interest to generate several instances of random data, to be used to probe an algorithm. The corresponding method is SBL::Batch_manager::BM_Batch::repeat:
batch.repeat(10)
In this case, each output data directly created in the output directory of the batch is suffixed with _instance_n , where n is replaced by the number of the instance of the execution that generated this data.
If one wants to create scripts for running each execution separately (e.g when using other systems for running the batch, as QSUB ), the method make_scripts create one program python script for each execution:
batch.make_scripts()
This will print in the output directory of the batch one file per execution with the name run_<output_directory_name>_<index> , where the index identifies the execution among all the executions of the batch.
Finally, it is possible to split a batch as mentioned in section Batches, and run them separately:
for b in batch.split_per_NFO(): b.run()
for b in batch.split_per_IFO(): b.run()
for b in batch.split_per_selected_option("option-name"):
b.run()
for b in batch.split_per_selected_options(["option-name-1", "option-name-2"]): b.run()
In all cases, one output directory is created per batch with the convention of the section Batches
In the following, we present three examples using Batch_manager : the first one manually specifies a batch; the second one uses a run specification file to specify calculations; the third one uses two specification files to couple a step of data creation and a step of data processing.
This example shows how to specify one run of an application computing the volume of a molecular structure, and run the batch.
This example shows how to specify a batch using a run specification file and a dataset, then how to split the batch, and then run the splited batches. The first file corresponds to the run specification file of the application computing the volume of a molecular structure. The second file is the python script running the batches.
In this example, Batch_manager is first used to generate data using one program (dumping a collection of balls into a file), and then to process these data using a second program (computing the volume of the union of balls generated).
This pipeline requires two specification files, namely one to generate the input balls, and one to compute the volumes.
The four files below are as follows: first, the python script generating the balls; second and third, the two specification files, and fourth, the main python script.
In this example, Batch_manager is first used to generate data using one program (dumping a collection of 2D points into a file), and then to process these data using a second program (clustering those points following their proximity in space). A Python script is then called for visualizing the clusters. Finally, the clusters from the different data, are compared two by two.
There are two tricks in this pipeline.
The visualisation script requires three input files :
If one wants to run several times the clustering with different parameter values, then we obtain several clusters and centers files : we do need to specify how these fiels are associated. Moreover, if several original points are generated, we need to associate each origin points files to a set of tuples of clusters and centers.
The comparison program requires two input graphs as input, each graph being represented by three input files :
This pipeline requires four specification files, namely one to generate the input points, one to compute the clusters, one to visualize them, and one to compare the clusters.
The five files below are as follows: the four specification files and the main python script;
In addition to SBL::Batch_manager::BM_Batch, the Batch_manager package involves four main classes:
As mentioned in the section Programmer's Workflow, when loading a dataset, the absolute path to each input file is stored. When setting the name of an output file from the name of an input file, make sure to remove the directory prefix, so as to keep the filename only.
See the following jupyter demos:
This first example shows how to specify one run of an application computing the volume of a molecular structure, and run the batch. In this example, all options are passed directly to the batch manager.
from SBL import Batch_manager
from Batch_manager import *
print("Marker : Calculation Started")
batch = BM_Batch()
batch.add_run_specification(BM_Run_specification_tuple("sbl-vorlume-pdb.exe"). \
add_option("output-prefix").add_option("log").add_file_option("f", "data/1vfb.pdb"))
batch.run_specifications.run("results", 1)
print("Marker : Calculation Ended")
In general, it is more convenient to store all options in a specification file. This example shows how to specify a batch using a run specification file and a dataset, then how to split the batch, and then run the splited batches. The specification file corresponds to the computation of the volume of a molecular structure. The content of the specification file batch-vorlume-pdb.spec is shown below :
#The executable.
EXECUTABLE sbl-vorlume-pdb.exe
#Any .pdb file from the dataset is elibigle for the option -f, as specified by the python regex.
#NB: the dataset name is specified when constructing the batch in the python script.
IFO f "\.pdb$"
#There is a unique IFO, with one execution per value i.e. file.
IFO-ASSOC-RULE unary
#These are the Non File Options for the executable.
NFO log
NFO output-prefix
NFO verbose
NFO water
NFO radius 0 1.4
NFO p 4from SBL import Batch_manager
from Batch_manager import *
print("Marker : Calculation Started")
batch = BM_Batch()
batch.load_dataset("data", ".*", True)
if batch.load_run_specification("batch-vorlume-pdb.spec"):
batches = batch.split_per_NFO()
for b in batches:
b.run()
print("Marker : Calculation Ended")
In this example, Batch_manager is first used to generate data using one program (dumping a collection of balls into a file), and then to process these data using a second program (computing the volume of the union of balls generated).
This pipeline requires two specification files, namely one to generate the input balls, and one to compute the volumes. The specification file batch-generate-balls-3.spec to generate balls goes as follows:
#The executable.
EXECUTABLE generate-random-balls-3.py
#There is no Input File Option.
IFO-ASSOC-RULE none
#The S and s parameters are specified by pairs of values: five pairs here.
NFO (number, max-radius) (100, 1) (200, 2) (500, 3) (1000, 4) (10000, 5)
#The centers of the 3D balls are generated in [0,10] x [0,10] x [0,10].
NFO box-size 10The computation of the volumes is specified as follows in batch-vorlume-txt.spec:
#The executable.
EXECUTABLE sbl-vorlume-txt.exe
#Any .txt file from the dataset is elibigle for the option -f, as specified by the python regex.
#NB: the dataset name is specified when constructing the batch in the python script.
IFO f "\.txt$"
#There is a unique IFO, with one execution per value i.e. file.
IFO-ASSOC-RULE unary
#These are the Non File Options for the executable.
NFO log
NFO output-prefix
NFO verbosefrom SBL import Batch_manager
from Batch_manager import *
print("Marker : Calculation Started")
batch_data = BM_Batch()
batch_data.load_run_specification("batch-generate-balls-3.spec")
output_dirs = []
for b in batch_data.split_per_NFO():
b.repeat(10)
output_dirs.append(b.get_output_directory())
batches = []
for directory in output_dirs:
batches.append(BM_Batch())
batches[-1].load_dataset(directory)
batches[-1].load_run_specification("batch-vorlume-txt.spec")
batches[-1].run()
print("Marker : Calculation Ended")
In this example, Batch_manager is first used to generate data using one program (dumping a collection of 2D points into a file), and then to process these data using a second program (clustering those points following their proximity in space). Finally, a data comparison is performed (the clusters of points are compared two by two).
If one wants to run several times the clustering with different parameter values, then we obtain several clusters and centers files : we do need to specify how these files are associated. Moreover, if several original points are generated, we need to associate each origin points files to a set of tuples of clusters and centers.
The comparison program requires two input graphs as input, each graph being represented by three input files :
the points file specifying the points to be compared–these are vertices of a graph.
the weights file which assigns a weight to each point (the size of the corresponding cluster).
the edges file which links points (i.e. clusters). To compare two clustering, we therefore need to compare all possible combinations of those tuples.
This pipeline requires three specification files:
specification of the execution of the random 2D points generator batch-generate-points-2.spec
#The executable.
EXECUTABLE generate-random-points-2.py
#There is no Input File Option.
IFO-ASSOC-RULE none
#The S and s parameters are specified by pairs of values: five pairs here.
#NFO (N,d) (10,2) (10,3)
NFO N 1000
NFO d 2 4 6specification of the execution of the cluster machine batch-cluster.spec
#The executable.
EXECUTABLE sbl-cluster-MTB-euclid.exe
#There is a unique IFO, with one execution per value i.e. file.
IFO-ASSOC-RULE unary
IFO points-file "\.txt$"
NFO num-neighbors 4
NFO persistence-threshold 0.1
# output files with proper prefix
NFO ospecification of the execution of the comparison of the clusters batch-compare-clusters.spec
#The executable.
EXECUTABLE sbl-emd-graph-euclid.exe
#We which to make all combinations of pairs of the next IFO
IFO-ASSOC-RULE combinatorial 2
IFO (vertex-points-file, vertex-weights-file, edges-file) "N\d+-d\d+.*persistence_0dot\d+" ("points\.txt", "weights\.txt", "edges\.txt")
NFO v
NFO u
NFO with-connectivity-constraints 1 0from SBL.Batch_manager import *
print("Marker : Calculation Started")
batch = BM_Batch()
batch.load_run_specification("batch-generate-points-2.spec")
batches_d = batch.split_per_selected_option("N")
odirs_data = []
for b in batches_d:
b.run()
odirs_data.append(b.get_output_directory())
odirs_clust = []
for directory in odirs_data:
batch = BM_Batch()
batch.load_dataset(directory, ".*.txt", False)
batch.load_run_specification("batch-cluster.spec")
batch.run()
odirs_clust.append(batch.get_output_directory())
for directory in odirs_clust:
batch = BM_Batch()
batch.load_dataset(directory, ".*.txt", False)
batch.load_run_specification("batch-compare-clusters.spec")
batch.run()
print("Marker : Calculation Ended")